이 글은 DMQA 김성범 교수의 ARIMA Model-Part 2, 시계열 분석 실습 6장 시계열의 통계적 모델, POSTECH 전치혁 교수의 비정상 시계열 4주차를 기반으로 작성되었습니다.
시계열 분석 3주 차에는 ARIMA에 대한 연구를 진행했습니다.
특히, 과도기 보정 / ARIMA 모델 / SARIMA 모델 그것에 대해 배웠습니다.
S&P 500 주가 데이터를 이용한 모델 구현 https://github.com/loiswoo/Time-Series/blob/main/TS_study_w3.ipynb에서 찾을 수 있습니다
자기회귀 통합 이동 평균(ARIMA)
ARMA 모델에서 추세를 제거하고 시계열을 정규화하는 차이까지 고려한 모델입니다.
ARIMA는 정상성을 만족하는 데이터에 대해 차분을 계속합니다.
ARIMA 모델은 (p, d, q) 매개변수로 구성됩니다.
AR(p): 독립변수의 개수
I(d): 미분 수
MA(q) : 파라미터 개수
• 차이 차수가 너무 커서는 안 됩니다.
• ARIMA 매개변수 값은 과도한 복잡성과 샘플 데이터에 대한 과적합을 피하기 위해 가능한 한 작게 유지되어야 합니다.
• p > 5; d > 2이고 q > 5이면 회의적인 것이 좋습니다.
• 항 p 또는 q 중 하나만 큰 값으로 설정하고 나머지는 상대적으로 작은 값으로 설정하는 것이 좋습니다.
• ARIMA(0,0,0)는 백색 잡음 모델입니다.
• ARIMA(0,1,0)는 랜덤 워크입니다.
• ARIMA(0,1,1)는 지수 평활 모델입니다.
• ARIMA(0,2,2)는 추세 지수 평활 데이터로 확장된 Holt의 선형 방법입니다.
분화: 비정적 데이터를 고정 데이터로 변환
현재 데이터에서 d 지점 이전의 데이터를 뺀 값
1. 차이점: 차원 t의 데이터와 차원 t-1의 데이터
→ 차분에 의한 Stationary 데이터 생성 가능
– 평균값이 일정하면 1차차로도 충분
– 시간에 따라 달라지는 추세가 있다면 두 번째 차이로 계속 진행
대부분의 데이터의 경우 두 번째 차이로 충분합니다.
세 번째 차이를 만들어야 하는 경우 ARIMA 모델 자체가 적합하지 않습니다.
1. 모델을 수동으로 조정하는 방법 – Box-Jenkins ARIMA 방법
1. 데이터 전처리(변환, 차별화)
비정상 데이터는 ACF 플롯에서 천천히 감소하는 모양을 보여줍니다.
따라서 차이를 형성하여 정지된 방식으로 변경할 수 있습니다.
정적일 때 Lag2의 급격한 하락이나 ACF 플롯의 규칙적인 패턴이 없습니다.
2. 잠정적으로 관리할 모델 식별
그래픽 방법을 사용하십시오.
| 모델 | ACF | 부분 ACF |
| MA(q) | 지연 q 후 차단 | 소멸(기하급수적으로 감소하는 사인 함수 형태) |
| AR(피) | 소멸(기하급수적으로 감소하는 사인 함수 형태) | 시차 p 이후 잘림 |
| ARMA(p,q) | Extinction (시차 qp 이후 사라짐) | Extinction (시차 qp 이후 사라짐) |
3. 추정 매개변수
이것은 ARIMA(p,d,q)에서 모수를 추정하는 과정입니다.
일반적으로 d=1 또는 2 사이에서 결정이 내려집니다.
그리고 p: 1~20, q: 1~20으로 설정한 후 for 루프를 실행합니다.
AIC 또는 테스트 정확도는 최적의 시간에 설정할 수 있습니다.
4. 진단 점검 (2번으로 돌아갈 수 있음)
모델의 적합성을 확인해야 합니다.
1) 잔차를 찾고 2) 잔차의 ACF 플롯을 확인합니다.
→ 40개 중 2~3개만 빠져야 합니다.
잔차 플롯(ACF)을 그릴 때 잔차(오차 항) 간의 자기 상관 패턴이 표시되지 않아야 합니다. 패턴이 나타나는 경우 잔차의 자기 상관을 처리하기 위해 모델에 추가 항을 포함하여 복잡성을 높이는 것을 고려하십시오.
모델 예측과 실제 값 간의 상관 관계를 분석하여 모델을 빠르게 비교/선택할 수 있습니다. 예측값과 실제값의 상관계수가 상당히 크면 모델의 성능이 우수하다는 뜻이다. 그러나 상관계수가 이전 모델과 유사하다면 더 복잡한 모델을 선택할 필요가 없다.
5. 모델을 사용하여 예측
2. 모델 자동 맞춤 방법 – 예측 패키지의 auto.arima()
auto.arima()는 그리드 검색을 통해 AIC 최소화를 수행합니다.
계절 ARIMA 모델(SARIMA)
계절 ARIMA 모형은 기존 ARIMA 모형에 계절 변동을 반영한 모형입니다.
– SARIMA 모델은 독립적인 ARIMA 모델을 계절별로 조합한 모델입니다.
– SARIMA 모델은 곱셈 계절성을 가정합니다.
– 기존 ARIMA(p,d,q) 모형은 계절주기를 나타내는 차수 s가 추가로 필요하기 때문에
ARIMA(p,d,q)(P,D,Q)s로 표현 – 비계절 요인은 소문자, 계절 요인은 대문자
– s의 중요한 점은 모델이 시간적으로 인접한 날짜가 같은 계절에 있거나 다른 계절에 있더라도 일반적이고 시기 적절하게 상호 영향을 인식한다는 것입니다.
– s의 값은 월별 계절성을 나타낼 때 s=12, 분기별 계절성을 나타낼 때 s=4이다.
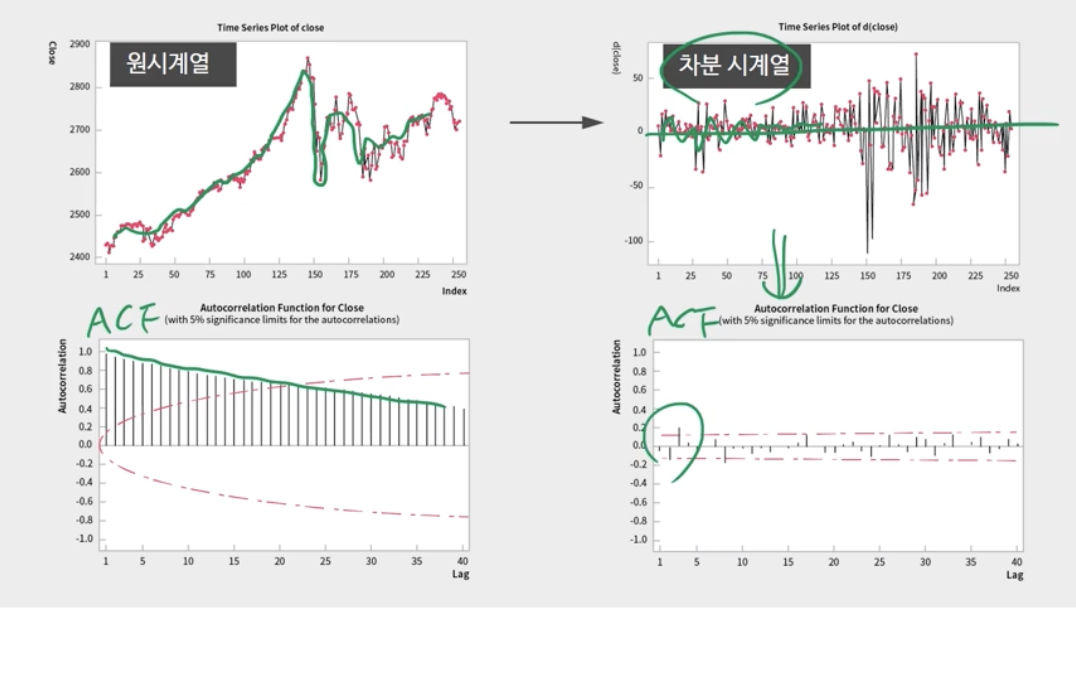
4-1 비정상적인 시계열 모델링을 위한 ARIMA 모델
시계열의 비정상성: 시계열에 추세 또는 계절성이 포함된 경우
1) 시계열 타임 플롯을 보고 시각적으로 평가
2) 시차 탐색값에서 ACF가 감소하는 패턴
3) 단위근 설정(버려도 단위근이 없으므로 정상)
1) 차이에 의한 고정 시계열로 변환
– 1차 차이: 시간 t와 시간(t-1)의 차이 계산
→ 정상적인 시계열을 나타내면 1차차이로 종료한다. 그렇지 않으면 2차 차이 프로세스입니다.
2) 함수 변환에 의한 분산 안정화
3) 분해는 추세와 계절성을 제거합니다.
– d 차수의 누적 시계열: d 차수의 차이 이후 처음 시계열이 정상일 때 원래의 시계열을 d 차수의 누적 시계열이라 하고 I(d)로 표시한다.
4-2 계절성을 반영한 ARIMA 모델의 이해
일반적으로 시계열, 추세 및 계절성은 종종 공존합니다.
추세는 차별화를 통해 제거할 수 있지만 계절성은 남을 수 있습니다.
ARIMA 모델은 비계절성 모델이므로 계절성은 별도로 처리해야 합니다.
일반적인 시계열은 비계절 ARIMA 모델과 계절 ARIMA 모델의 조합입니다.
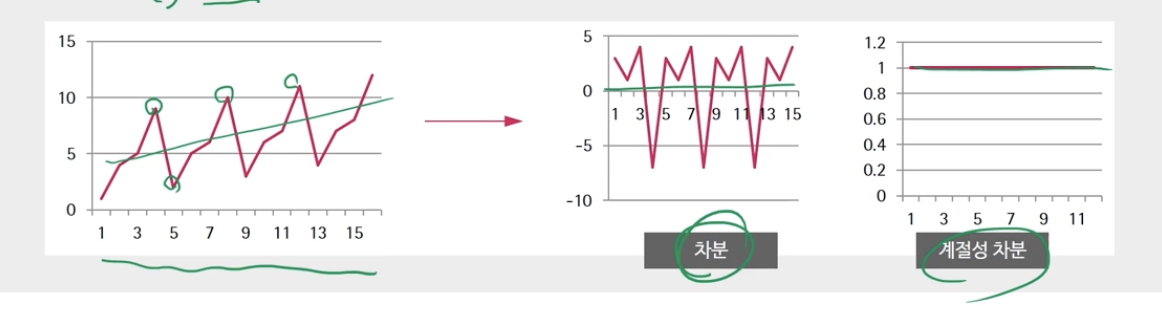
계절적 차별화
-시즌 기간 s (월간: s=12, 분기별: s=4)
-계절성이 있는 경우 단순(비계절성) 차별화가 정규화되지 않음
-First Order Seasonal Difference: 인접한 두 계절 값의 차이를 계산합니다.


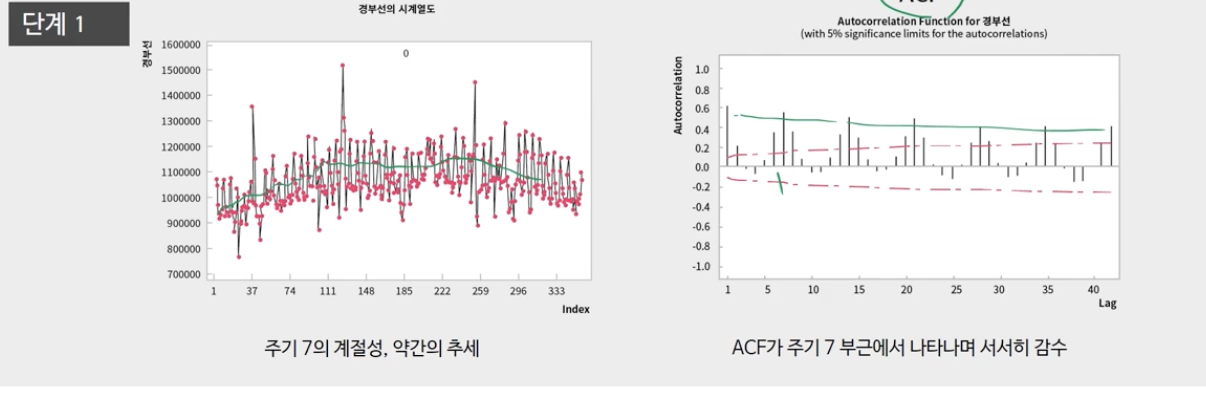
1. 시계열도를 그리고 추세와 계절성이 있는지 확인합니다.
2. 적절한 차별화
-추세와 계절성이 없는 경우: 기간의 계절적 차이
-추세가 있고 뚜렷한 계절성이 없을 때: 1. 곡선추세 차이 이전 선형추세 차이와 함수변환
– 추세 및 계절성: 먼저 계절성 발산을 수행하고 추세를 재검토합니다. 추세가 지속되면 첫 번째 차이를 추가합니다.
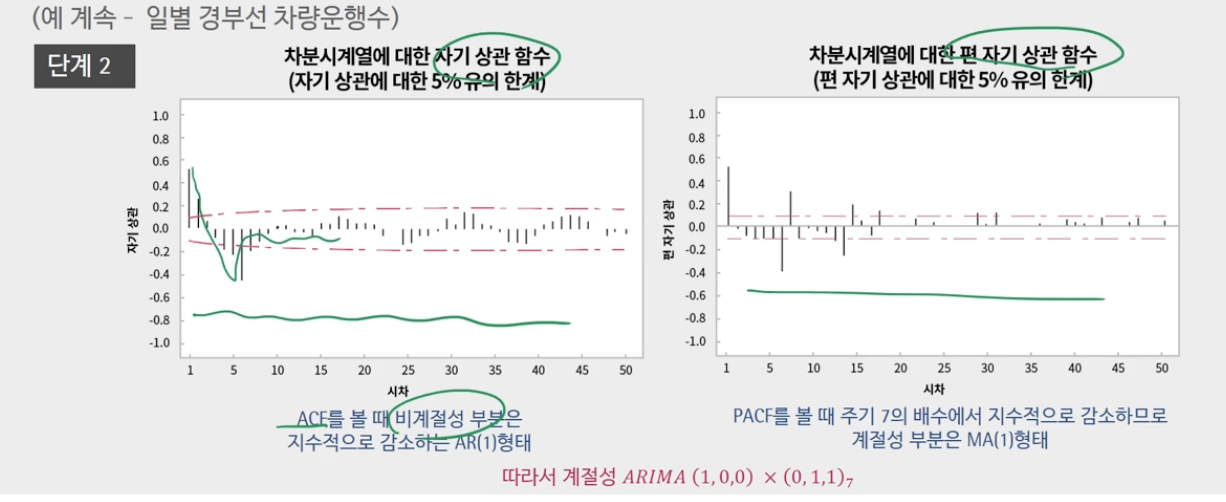
3. 미분 시계열에 대해 ACF 및 PACF를 기반으로 p,q,P,Q 결정
-비계절성 계수 p,q는 ARMA 모델의 경우와 동일하게 결정
– 주기의 배수로 나타나는 ACF와 PACF의 패턴을 고려하여 계절성 계수 P, Q를 결정
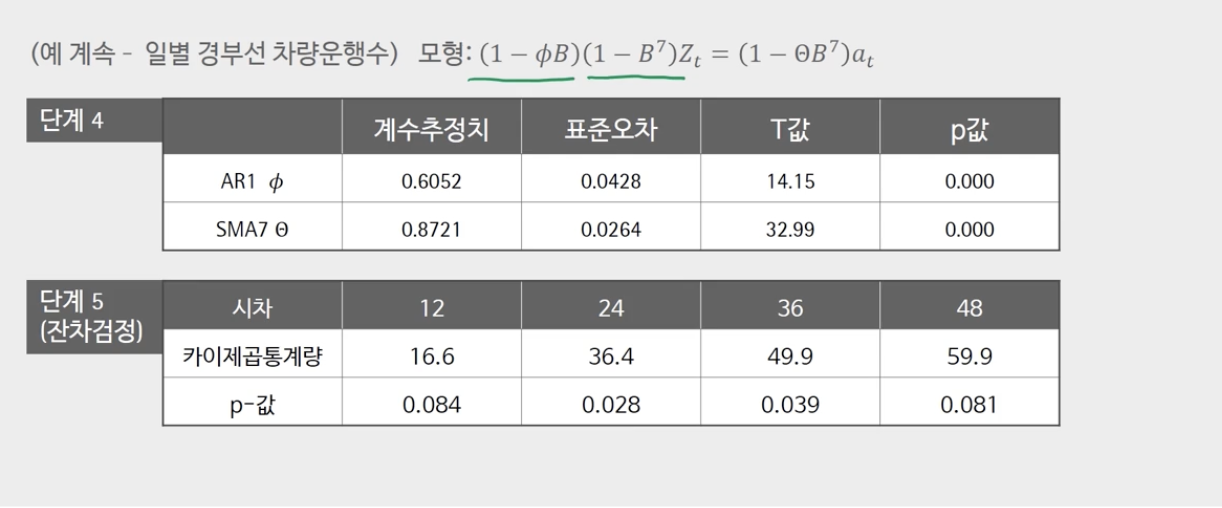
4. 모델 매개변수 추정
5. 잔량 테스트 실시
비정상성 검정을 위한 4-3 단위근 검정
단위근 검정은 통계 검정에 의해 시계열이 정상인지 여부를 결정합니다.
– 대표적인 단위근 검정은 ADF 검정이다.
-Dickey와 Fuller는 AR(1) 모델을 제안했습니다.
-고차원 AR 모델로 모든 고정 시계열을 근사화할 수 있다고 가정합니다.

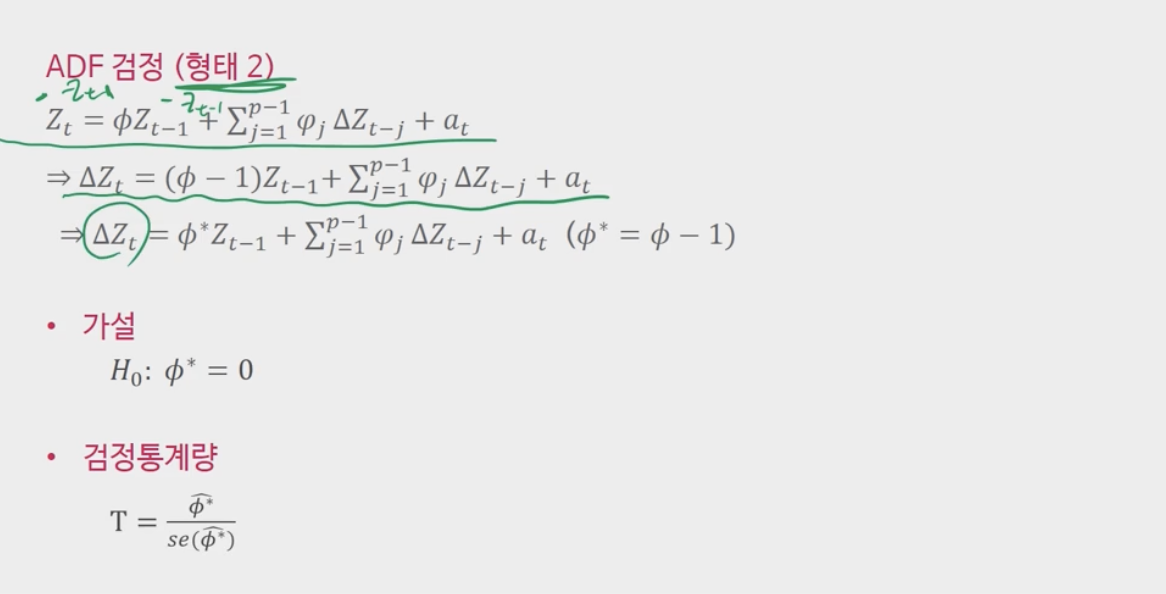
데이콘 주가예측 종목을 참고해 삼성전자가 주관했다.
https://dacon.io/en/codeshare/2570
(파이썬) 삼성전자 주가 예측
dacon.io
AR: 자신의 과거를 정보로 활용하는 개념 / “현재 상태는 이전 상태를 참조하여 계산됩니다.”
MA: ‘현재 용어의 상태를 추론하려면 이 용어의 오류를 사용하십시오.’
ARIMA: 추세 변동 경향을 반영하는 방법
ARIMA의 클래스 순서 = (2,1,2)
p: “AR이 과거를 얼마나 자주 들여다보는지에 대한 매개변수”
d: 차이에 대한 매개변수(차이: 현재 상태변수에서 이전 상태변수를 빼는 것, 시계열의 불규칙성을 수정하는 역할)
q: MA가 과거를 들여다보는 빈도에 대한 매개변수
1. p와 q의 합이 2보다 작은 경우
2. p와 q의 곱이 짝수(0 포함)인 경우
불규칙한 시계열 예측의 경우 먼 미래를 예측하는 데 그다지 중요하지 않기 때문에 “다음 N일 동안 어느 정도 증가/감소할 것”과 같은 대략적인 추세 예측만 하는 것이 일반적입니다.
모델 평가 프로세스
– model_fit.forecast(steps=5)로 향후 5일간의 가격을 예측하고 이를 pred_y로 정의
-Bitcoin_df.iloc(361:)은 bitcoin_df의 마지막 5일을 test_y로 정의합니다.
– 모델의 예측 상한 및 하한을 pred_y_upper 및 pred_y_lower로 정의합니다.
– 정의된 모든 값을 비교하여 5일 상승 추세 예측이 얼마나 정확한지 평가합니다.
모델 2: 페이스북 예언자
Prophet: 시계열 데이터의 추세(연/월/일) 예측에 중점을 둔 추가 모델이라는 모델링 기법을 기반으로 하는 시계열 예측 모델입니다.
+) Additive Model: 선형 회귀 분석의 단점을 극복하기 위해 개선된 분석 방법 -> 각 특징에 대해 비선형 피팅이 가능한 일련의 방법
fbprophet 라이브러리 – 데이터 프레임 속성을 ‘ds’ 및 ‘y’로 변경 / Prophet 클래스 선언 / fit() 함수를 사용한 모델 교육
매개변수
1) seasonity_mode: 연간, 월간, 주간, 일간 등 트렌드를 반영하는 수단 -> 각 순서에 따른 트렌드 확인 가능
2) changepoint_prior_scale: 트렌드가 변화하고 있는 맥락을 반영하는 파라미터. 숫자가 높을수록 모델이 과적합에 가깝습니다.
모델의 성능을 향상시키는 방법
1) 상한 또는 하한 설정
이는 하한선이나 상한선이 없는 주가 데이터에는 적합하지 않을 수 있지만 시계열 데이터에 상한선이나 하한선을 설정하는 것은 모델의 성능을 향상시키는 방법 중 하나입니다.
예) Prophet 모델: future_data(‘cap’) = 96000 으로 캡 설정 / 모델에 growth=”logistic” 파라미터 설정
2) 이상치 제거
이상치 설정 후 이상치에 해당하는 데이터 = None 설정